

Together with a large organization, we’re building a platform that presents company data to its data scientists so they can use it to develop innovative applications.
To handle huge amounts of data, we’re collecting the data in a generic format on a central Hadoop cluster. We do this using Spark, because it allows us to process this data in a performant way.
This presents quite a few challenges, one of which we’ll discuss in this blog post: how do you efficiently process data that includes escaped newlines? Read on to find out why this isn’t a trivial issue and how it can be solved.
Spark under the hood
A file located on HDFS (Hadoop File System) will be ‘physically’ split into multiple blocks and stored on separate data nodes. Using data locality, Spark can read those files in a performant way (to transform, for example). Instead of copying file blocks to a central compute node (which is expensive) you’re sending your logic to data nodes. The distributed code processes the blocks simultaneously, which is very efficient.
For every node to process its own bit of data (and to avoid double duty) the data has to be logically split into chunks. Every chunk is read by a single node and processed.
Ideally, a chunk corresponds to the data that is present on the node (an HDFS-block), but that is rarely the case. Hadoop divides a file into blocks based on bytes, without taking into account the logical records within that file. That means that the start of an HDFS-block typically contains a remainder of the record from a different HDFS-block, while the last record is typically not fully contained within the block.
The image below of Hadoopi shows this for a file of 300 MB, containing 6 records of 50 MB each. Hadoop has split this file into 3 blocks of max. 128 MB. In this case, the 3rd and 6th record have been split over several HDFS-blocks.
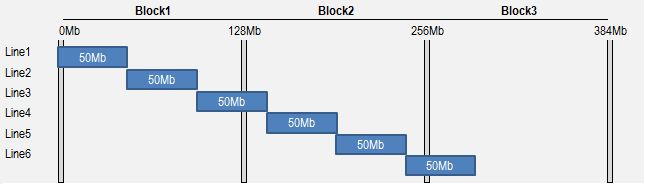
To process this file, Spark will create executors on each of the nodes on which this file is stored. These executors are responsible themselves for deducting the logical chunk from the file.
- Executor 1 on Block 1 has to view the first 3 blocks as its chunk
- Executor 2 on Block 2 has to view the last 3 blocks as its chunk
- Executor 3 on Block 3 has to realize that there are no records that start on its node, so it doesn’t need to process any data.
Executor 1 can read its first two records locally. To read the third record, it has to go and read a bit ‘remotely’ on the node of Block 2. The added overhead is ok; that last bit will usually be as large as half of the record. That’s because, worst case, Executor 1 has to read the full last record on Block 2. This can’t be optimized out of the gate, but that isn’t necessary: its record size is quite small compared to that of a block.
Back to the problem at hand
Spark allows us to process chunks of logical records simultaneously. It’s crucial that Spark knows how to recognize the records. This happens by assuming that each record has its own ‘line’ in a file. So, Spark scans the data for newlines and uses those positions as the boundary between 2 records. Spark allows for the use of a different record delimiter than the standard newline one, but in this example, that’s exactly the delimiter that’s been used.
What Spark cannot do, is recognize an escaped delimiter. If a record is a chat message, for example, then it’s possible that the message itself contains newlines. Typically, these newlines will be escaped by a backslash. These newlines are functionally relevant and as such should not be interpreted by Spark as a division between 2 records:
{from:"Gert", to:"Melissa", message:"Want to have dinner?"}
{from:"Melissa", to:"Gert", message:"Ok\
How about Italian?"}
Spark will erroneously spot 3 logical records because the escape-character \ is being ignored.
How do we solve this?
By preprocessing the data you can probably also achieve the intended result, but what we really want is a correct way to interpret the logical records. Luckily, this can be done fairly easily by writing some code ourselves. So let’s do this!
The Spark-framework can be used as an API from a programming language such as Scala. As an entry point to store data, you can use operations on a Spark-context:
val rdd = sparkContext.textFile("data.txt")
If so, Spark will define an RDD for your file with the assumption that each logical record is on a new line.
Using this code, however, you can use a so-called FileInputFormat class (developed yourself or not) to read your file:
val conf = new Configuration(sparkContext.hadoopConfiguration)
val rdd = sparkContext.newAPIHadoopFile("data.txt", classOf[MyFileInputFormat],
classOf[LongWritable], classOf[Text], conf)
This looks a lot more complex, but it simply says that you want to read your file using MyFileInputFormat and that the result should be an RDD of the (LongWritable, Text) type. This is a key-value structure in which the value will contain your logical record.
As such, such a FileInputFormat class is not magic:
class MyFileInputFormat extends FileInputFormat[LongWritable, Text]
override def createRecordReader(split: InputSplit, context: TaskAttemptContext): RecordReader[LongWritable, Text] = new MyRecordReader()
}
As you can see, the most important task of a FileInputFormat class is creating a RecordReader. Here, magic does happen. Let’s have a closer look, but keep in mind that the code shown below has been modified to be readable on a blog and that irrelevant code has been left out.
Where the magic happens
A RecordReader is an object with a number of operations you have to implement yourself.
class MyRecordReader() extends RecordReader[LongWritable, Text] {
// your implementation
...
}
You can look at this object as a kind of complex iterator to which you can always query the next logical record. Spark does this by calling the following operations:
- initialize(InputSplit, TaskAttemptContext): is the first one called. Here you decide which data you’ll have to read.
- nextKeyValue(): Boolean: is called several times until the operation returns as false. Here you put the next key-value, as long as it’s there in a particular chunk (in code this is called an InputSplit).
- getCurrentKey(): LongWritable: returns the key that was found last.
- getCurrentValue(): Text: returns the value that was found last.
There are also some operations to close the RecordReader or to know the progress within the input split, but these aren’t relevant for this post.
Our problem is that Spark does not detect whether a delimiter (in our case a newline) is ‘escaped’ or not. To solve this, we need to find the correct starting point of the first logical record and read every logical record correctly.
Let’s have a closer look at the initialize operation:
var start, end, position = 0L
var reader: LineReader = null
var key = new LongWritable
var value = new Text
override def initialize(inputSplit: InputSplit, context: TaskAttemptContext): Unit = {
// split position in data (start one byte earlier to detect if
// the split starts in the middle of a previous record)
val split = inputSplit.asInstanceOf[FileSplit]
start = 0.max(split.getStart - 1)
end = start + split.getLength // open a stream to the data, pointing to the start of the split
val stream = split.getPath.getFileSystem(context.getConfiguration)
.open(split.getPath)
stream.seek(start)
reader = new LineReader(stream, context.getConfiguration) // if the split starts at a newline, we want to start yet another byte
// earlier to check if the newline was escaped or not
val firstByte = stream.readByte().toInt
if(firstByte == '\n')
start = 0.max(start - 1)
stream.seek(start)
if(start != 0)
skipRemainderFromPreviousSplit(reader)
}
def skipRemainderFromPreviousSplit(reader: LineReader): Unit = {
var readAnotherLine = true
while(readAnotherLine) {
// read next line
val buffer = new Text()
start += reader.readLine(buffer, Integer.MAX_VALUE, Integer.MAX_VALUE)
pos = start // detect if delimiter was escaped
readAnotherLine = buffer.getLength >= 1 && // something was read
buffer.charAt(buffer.getLength - 1) == '\\' && // newline was escaped
pos <= end // seek head hasn't passed the split
}
}
This looks heavy, but essentially, this is what happens:
- We receive an input split (HDFS block) as parameter from which we pull the start and end points of the split. The split can start in the middle of a logical record. In that case, that record starts in the previous input split and will be processed by a different executor. The current executor needs to ignore this record.
- To determine whether the current split starts in the middle of a logical record, we want to have a look at the final byte of the previous split. That’s why we start to read 1 byte earlier, so we’re sure that we’re starting to read in the record of a previous split.
- Special case: we read that particular byte (which is located right before the current split) and check whether this is a newline. If so, we’ll start to read yet another byte earlier, because of the possibility that the newline is escaped.
- Finally, we read one full record from the point where we’re currently located, i.e. 1 or 2 bytes before the current input split. This way, we read the last bytes of the last record from the previous split. Where that record ends, the first record of the current split starts. It can start at 0, 1 or 193 bytes following the starting point of the split.
- Beware: the above and the reading of the first record does not happen when the input split is the first split of the data. In that case, we can simply start to read from byte 0.
The record reader is now all set to read key-value after key-value.
override def nextKeyValue(): Boolean = {
key.set(pos)
// read newlines until an unescaped newline is read
var lastNewlineWasEscaped = false
while (pos < end || lastNewlineWasEscaped) {
// read next line
val buffer = new Text
pos += reader.readLine(buffer, Integer.MAX_VALUE, Integer.MAX_VALUE)
// append newly read data to previous data if necessary
value = if(lastNewlineWasEscaped) new Text(value + "\n" + buffer) else buffer
// detect if delimiter was escaped
lastNewlineWasEscaped = buffer.charAt(buffer.getLength - 1) == '\\'
// let Spark know that a key-value pair is ready!
if(!lastNewlineWasEscaped)
return true
}
// end of split reached?
return false
}
What happens here is simple. You read line after line and check each time whether the last newline was escaped or not. If that’s not the case, you know that you’ve fully read a logical record and you can let Spark know that that a key-value is ready to be used.
How can we test this?
This whole story deals with features of a Hadoop cluster, namely that a file is split across various machines. That’s why it’s useful to use multiple executors and to read the data via input splits.
Luckily, the code can be tested automatically on a laptop or a build server, without needing a physical cluster with large files and multiple nodes. You can create your own input splits and run your RecordReader on them:
class MyRecordReaderTests extends FunSuite {
// other tests
...
test("I should be able to read an input split") {
val split = new FileSplit(path, 2750, 4085, null)
// setup
val context = setupTaskAttemptContextImpl()
val reader = new MyRecordReader()
// initialize
reader.initialize(split, context)
// read all records in split
val actual = new mutable.ListBuffer[(LongWritable, Text)]()
while(reader.nextKeyValue())
actual += (reader.getCurrentKey, reader.getCurrentValue)
// assert that data is what you expect
...
}
}
Conclusion
If you’ve made it all the way here, you’re probably dealing with a similar ingestion issue. In that case, I hope this blog has sparked you to tinker with a custom FileInputFormat yourself.
Because of the added complexity, we had some doubts at first if this was the right way to solve our problem, but in the end, we didn’t regret our choice one bit because it spared us from a few headaches. Of course, our automated tests also play their part.
So, good luck, and please share your experiences in the comments below.
Want to talk about the innovative things that can be done with your data? Let's talk.



