

In December 2019, Cloudbrew took place in Mechelen (Belgium). Hosted by the AZUG user group and proudly sponsored by AE, Cloudbrew is an annual – and free – two-day cloud conference that focuses on all things Microsoft Azure. This year’s edition saw Koen Verbeeck, one of our very own consultants, take to the stage with a session on ‘Moving Data around in Azure’, in which he explored some of the various methods of moving data from one service to another. Did you miss out on the event? Not to worry. In this blog post, we gladly summarize Koen’s findings for you!
To code or not to code
Before we start our summary, we’d like to point out that two different kinds of services exist in Azure:
- Services that require you to write code, e.g. Azure Functionsand Azure Databricks.
- Services for which you don't need to write code (a few simple expressions aside). Think Azure Logic Apps and Azure Data Factory, for instance.
1. Writing Code
Azure Functions
In two words, this method comes down to serverless compute. You write a piece of functionality, for example converting a .csv file to JSON or reading a file from blob storage and then writing its contents to an Azure SQL Database. By deploying that piece of code to Azure, you enable other services to call your code to perform a task. A powerful advantage in this department is that Azure Functions are event-driven. You can, for instance, trigger an Azure Function by calling a webhook, but the function can just as well kick in each time a new file is added to a blob container.
There’s no need for scaling or to manage a server, as Azure handles it all for you. Azure Functions are fully supported in Visual Studio, so you can write, debug and test them in your familiar development environment. As a bonus, you get to enjoy full DevOps support. Moreover, Azure Functions support many different languages: C#, PowerShell, Python, Batch, Bash, JavaScript, PHP and F#.
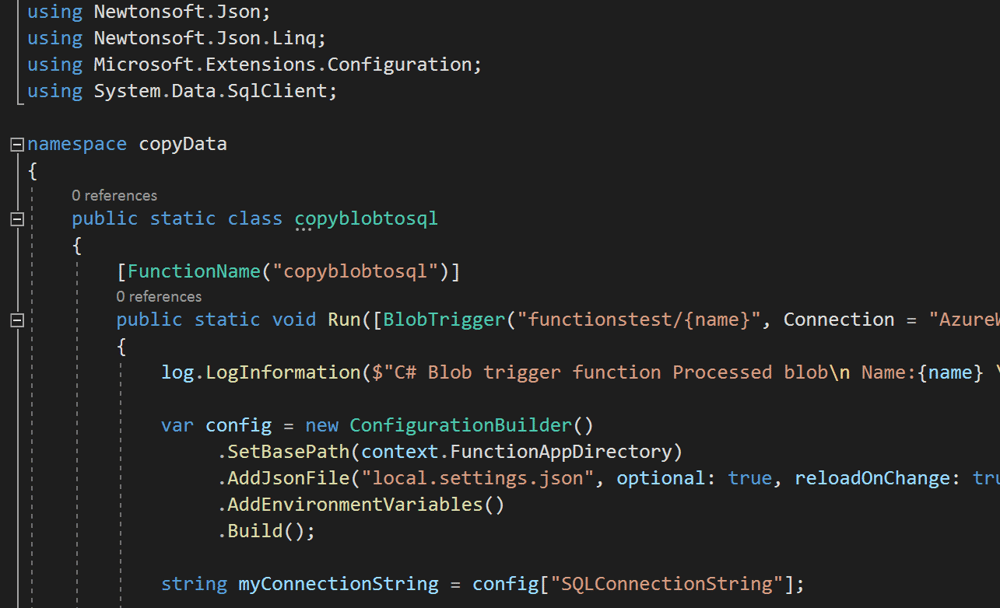
Azure Functions can be called from various other Azure services, such as Azure Data Factory and Azure Logic Apps – an easy way to extend those services with functionalities that may be lacking. Azure Functions are intended to be snippets of code with a short runtime, handling a specific task. For larger, longer running code, you may find Azure Batch a better solution.
Azure Databricks
First there was Hadoop, then there was Spark and now there is Azure Databricks. A commercial implementation of the open source Apache Spark platform, it is, briefly put, a unified analytics engine for big data.
You can use it to stream data, create machine learning models, create ad-hoc analysis over big data or you can use it as a data engineering solution (aka moving data around). The code to handle the data is written in notebooks, which are web-based interfaces to documents containing runnable code, visualizations and documentation. Here's an example:
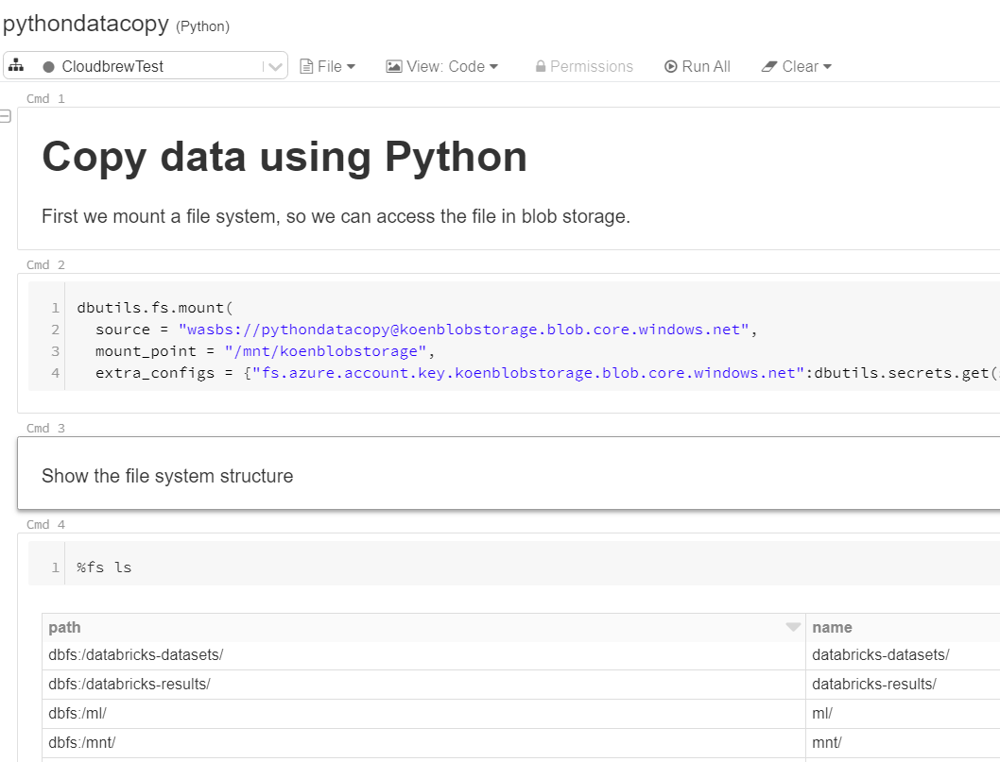
A notebook consists of various cells. A cell can contain code waiting to be executed, or just text. The beauty of these notebooks is that you can easily switch between different programming languages. There's always one default language for each notebook (Python in the example above), but you can, however, switch certain cells to Java, Scala (the Spark language) or SQL. This way, notebooks allow team members with different specialties to write code in the language they prefer.
Underneath the notebook runs a Spark cluster. It can auto-scale, but will also shut down automatically after a period of inactivity, saving you costs.
Azure Databricks has been on the rise for the past few years now, and it's definitely worth checking out since it can combine various use cases into one single platform.
2. Not writing code
Azure Logic Apps
Logic Apps is a workflow management tool that allows you to create and automate business processes, integrating SaaS and enterprise applications in a serverless environment. It's the Azure equivalent of Office 365 Flow, which has been renamed Power Automate.
Below is an example of a flow which refreshes a Power BI dataset in a workspace while also checking whether the refresh was successful. In case of failure, a notification is sent via email.
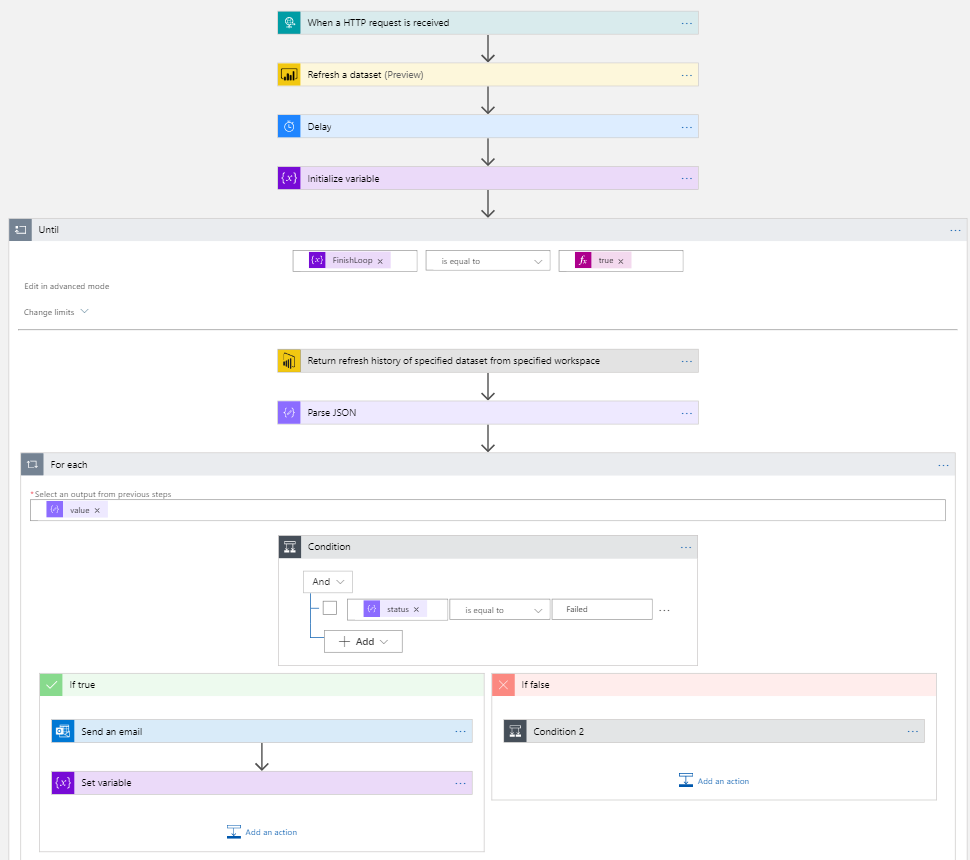
And all that without you having to write any code!
Like Azure Functions Logic Apps are event-based. They, too, are triggered by certain events, such as a call to a webhook. There are dozens of connectors and tasks for various services. Here a few examples of supported services.
- Power BI
- Azure Data Factory (and many other Azure services)
- Office Exchange (e.g. to send an email)
- SharePoint Online
- Adobe
- Box
- GitHub
- Google Drive
- MailChimp
- SAP
Azure Data Factory
In short, Azure Data Factory is the data movement service in Azure. It's a serverless elastic compute environment where you can create data pipelines.

Readers familiar with classic ETL tools like SQL Server Integration Services will certainly recognize the ‘arrows and boxes’ format. In Azure Data Factory, there are three different types of compute, called Integration Runtimes:
- The Azure Integration Runtime is what you’d call the default Runtime, handling all the compute of the activities in the pipelines (for as long as it’s required, that is. Executing a stored procedure will run in SQL Server itself and not in ADF, for example).
- The Self-hosted Integration Runtimeruns on-premises on one of your own services. This is useful if you want to dispatch compute activities locally instead of in the cloud (for example to process sensitive personal information). It can also serve as a gateway between Azure and your on-premises data sources. If you want to read data from a local SQL Server, for instance, you'll need this runtime installed on a local server.
- The Azure-SSIS Integration Runtime is a cluster of virtual machines capable of running SSIS packages. It comes in handy when you have existing SSIS projects which you want to migrate to the cloud. With this runtime, it's easy to lift-and-shift your projects to Azure Data Factory.
Different kinds of pipelines also exist:
- The ‘normal’ pipeline handles activities without moving data. You can compare it to a control flow in SSIS. Examples include starting a Logic App, executing an SSIS package, Databricks notebook or stored procedure, and so on. No data is read directly into ADF. An example of such a pipeline:

- The mapping dataflow. A special activity carried out by the normal pipeline, the mapping dataflow reads data into memory and enables you to perform transformations on the data directly in ADF. Similar to a dataflow in SSIS, the code is translated to Scale behind the scenes and executed on a Databricks cluster. Here's an example:

- The wrangling dataflow, another special activity of the normal pipeline. Contrary to the mapping data flow, which is more abstract, you can see the data while creating the transformations thanks to the Power Queryengine inside ADF (the same engine you use to read data into Power BI Desktop, for example). At the time of writing, this dataflow is still in preview.
Behind the scenes, every object in ADF is actually just JSON. ADF also supports source control and templates.
But wait. There's more!
Azure allows for many different methods to move data around. Describing every single one of them is, unfortunately, not feasible. In his session, Koen had to leave out various services, including:
- Very specific use cases, such as Azure Machine Learning, IOT Hub, Azure SQL Data Warehouse and so forth. Services like these automatically ‘dictate’ what method you'll be using to move the data, such as PolyBase for Azure SQL DW (now called ‘Azure Synapse Analytics’), for example.
- Anything running on a virtual machine hosted in the cloud, i.e. almost all software which can handle data.
- Back-up and migration services, such as Azure Data Box, AzCopyor Azure Database Migration Services. These services exist purely to get on-premises data into blob storage, data lake storage or SQL Server.
The bottom line is this
Azure offers many different options to move data around. If you’re dealing with big data or creating machine learning models, Azure Databricks makes for an excellent choice. In most other cases, though, Azure Data Factory (ADF) is your number one solution. You may consider using ADF for big data engineering, too, since the mapping data flow in ADF is a visual layer on top of Azure Databricks.
Currently, however, ADF offers less options than Azure Databricks (there are, for example, less possible data sources in an ADF mapping dataflow than in Databricks itself). But perhaps the biggest difference to take into consideration is that ADF is easy to work with, while Databricks requires a certain level of coding skills. If you find some functionality is missing in ADF, you can easily extend it using Azure Logic Apps or Azure Functions.
Call to action
Keen to learn more? Excited to try out Azure but not sure how to get started? Feel free to contact us! We’re happy to give you a demo and answer all your questions.


