

GDPR Compliancy
May 25, 2018. This was the date every company and organization had to be GDPR compliant. What we see two years later is that many organizations still struggle to comply with the GDPR rules. Important concepts in the GDPR context are anonymisation and pseudonymisation. As such none of them is mandatory under GDPR. Securing and protecting data however is mandatory, and both anonymisation and pseudonymisation are effective methods to do so and therefore they are strongly recommended.
Pseudonymization consists of reversibly splitting people’s identifying data, using non-explicit pseudonyms (e.g. random strings) as the means of effecting the correspondence. By doing so exposure to identifying, or quasi-identifying, data is limited. Pseudonymization is reversible: you can find a person’s identity by recombining the the data (e.g. by making use of a correspondance table).
Data is considered anonymous when the person concerned is no longer identifiable by any means whatsoever and, no data or data set can be traced back to the person’s identity. Anonymization has to cover all recorded data, i.e. all data that could allow a person to be identified. As anonymization is, by definition, irreversible, it cannot generally be applied to production data used by business processes, because these would then be unusable. Therefore, what justifies anonymization rather than erasure of data is when it is to be used for:
- Software development and tests carried out during the software development cycle.
- Sharing documents with to a broader audience (e.g. contracts, application files, complaints,...).
- Analytics, statistical analysis and development of machine learning models.
In the latter case, if you’re trying to get insights out of your data, you’ll almost always end up with privacy issue at some point. Effectively, this is also the problem that we encountered when we were building a MVP of our Adore Platform (What is ADORE?).
Our own GDPR issues
At AE we wanted to automate some tedious tasks of our HR team using our own AI Powered Customer Care Agent ADORE. Most of the communication/questions to our HR team are done via e-mail. Collecting these mails was one of the first steps in building a model to automatically answer HR related questions. The information in these mails can be quite confidential. They can contain delicate information concerning our co-workers (wages, health-issues, …). We needed a way to "scramble" the sensitive parts of the mails such that we didn’t have to make a trade-off between the privacy of our co-workers and the way we want to build our machine learning models.
But… How can we work with this data and respect the privacy at the same time?
As a solution we built a GDPR Cleaning API that you can feed a sensitive mail or text and that returns the same mail or text but with the sensitive data replaced by a simple entity label. We wanted to try to automatically label those parts of the text which could lead us to identify a person. Thus, if a person is sharing sensitive information with HR, we would not be able to identify this person, and in this way respecting his/her privacy as much as possible. We identified some key entities which could identify a person in our organization:
- name
- license plate
- policy number
- address
- e-mail address
- URL
- telephone number
- national insurance number
- function title within the company
We used a combination of regex (pattern matching), open source data and Natural Language Processing (NLP) to identify these forms of sensitive data. Note that more data entities could lead to identifying a person in your organization (customer number, employer id, …). The GDPR API can of course be configured and expanded to also incorporate those patterns. We tested our API on 100.000 e-mails and we saw quite good results!
Okay, much blabla. Give me the action!
Let’s take an example mail. The choice of a mail in Dutch is because our API is now focused on Dutch. This is the case because the internal mailing inside our company was primarily Dutch. We are, however, working on the Natural Language processing models to also incorporate English and French as languages.
Hey Pol,
Dit is een voorbeeldmail om de functionaliteiten van de GDPR cleaner te tonen.Op dit moment woon ik in de Interleuvenlaan nummer 1 te Leuven. Mijn rijksregisternummer is 91.01.01-100.01 en de nummerplaat van mijn wagen is 1-ABC-123. Indien je nog vragen hebt over de GDPR API of het ADORE platform, stuur dan gerust een mailtje naar jos.pieters@ae.be of bel 0477/123456.
Groetjes, Jos
When all options, to identify and remove all key entities, are activated, we get the following output.

As you can see some of the sensitive data entities are present in the example mail. All of them have been detected and changed by a “#” followed by the entity type.
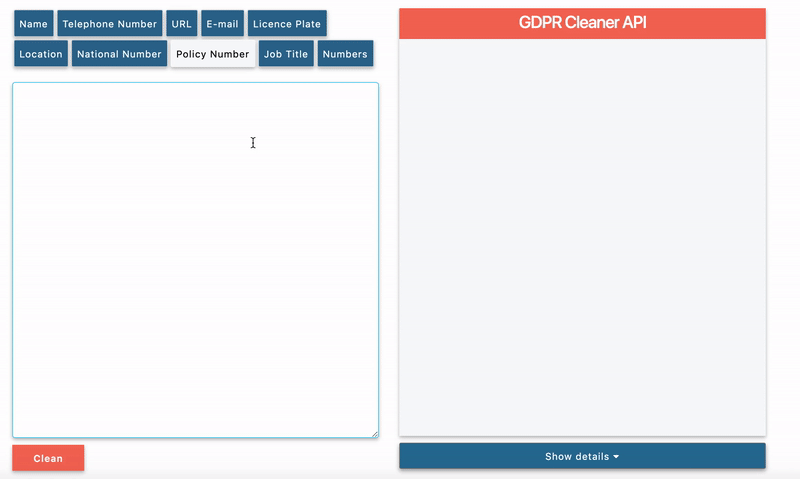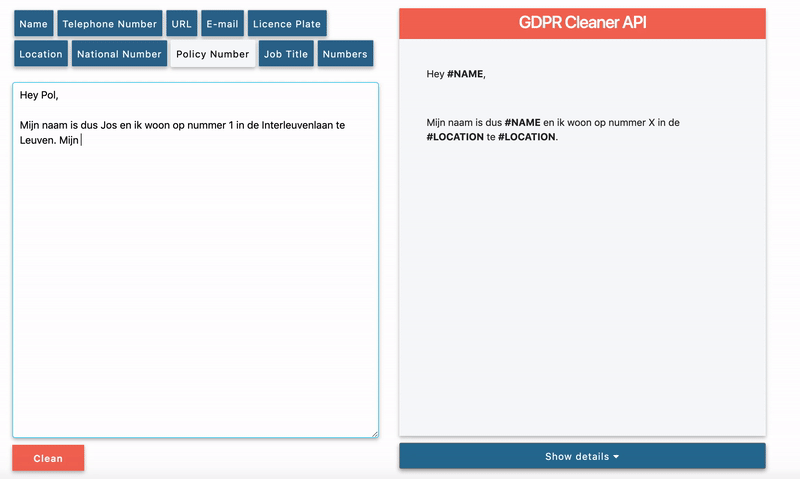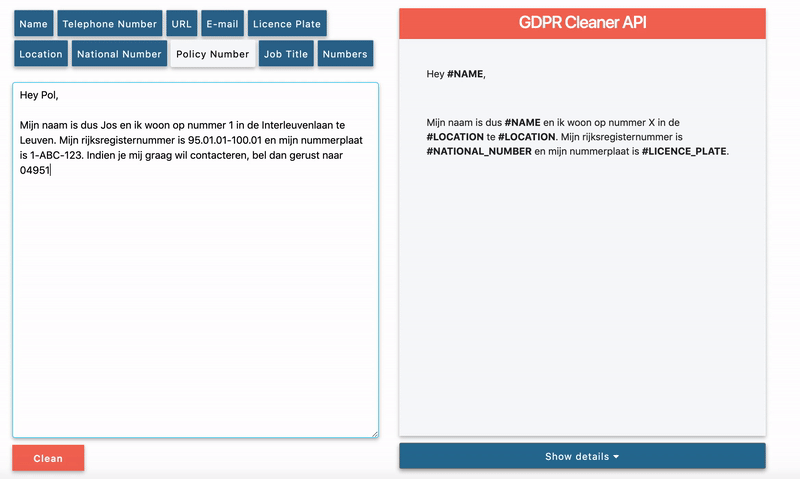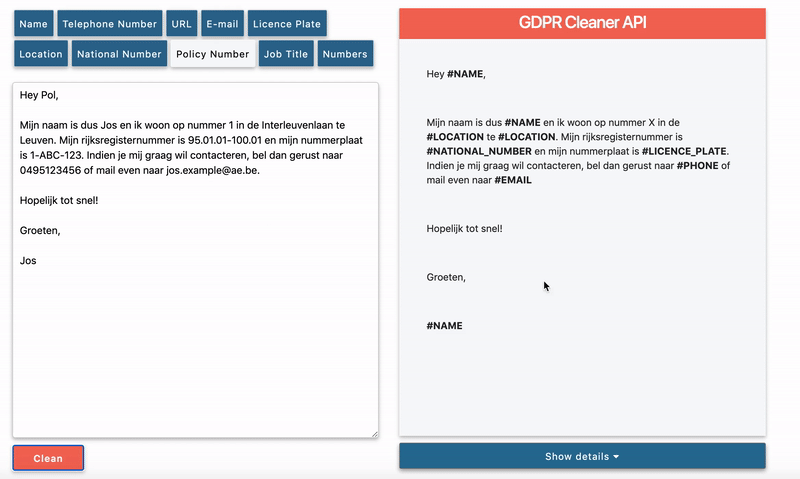
The API can be used to assist you both in anonymization and pseudonymization. The identified key entities can be thrown away or be stored separately to be used for re-identification later on. The latter option can be seen in the "Show details" field where all extracted entities are shown. Anonymisation and pseudonimisation are ofcourse only part of the story. Storing the identified key entities (and all other personal data you may have) in a secure and GDPR compliant way is crucial. For this task we rely on kuori, the state-of-the-art data platform which is flexible ecosystem of components to ingest, transform, store and publish data according to your (GDPR) needs.
Let me try!
Building a GDPR cleaner isn’t easy. We are well aware that more functionalities can be added and several improvements can be made, but our first version is quite doing the job though. Feel free to try it out for yourself and give us your feedback. You can access a limited demo version here.
If this API looks useful in your organization, feel free to reach out. We are happy to discuss any questions, specific requests or ideas you might have. You can find the latest up to date information on our GDPR Cleaner API web page.



