

Organisaties bezitten vaak veel data die opgeslagen wordt in ongestructureerde formaten. Vaak gaat het hierbij over data die mensen als vrije tekst hebben kunnen ingeven; denk hierbij bv. aan e-mails, call center logs, presentaties, handleidingen, etc. Analytics kan in deze situaties helpen om de waarde die verscholen zit in deze data toegankelijk te maken.
Als voorbeeld in deze blog nemen we de consultants van AE, die veel ervaring hebben opgedaan in verschillende technologieën en methodologieën. We helpen elkaar graag verder met vragen of problemen, maar het is niet altijd gemakkelijk om terug te kunnen vinden wie kan helpen met een bepaalde kennis of vaardigheid. Deze kennis zit verscholen in de CV's van de consultants, maar deze documenten zijn niet gemakkelijk structureel doorzoekbaar. Daarnaast zouden we ook graag een overzicht willen krijgen van hoe onze collega's zich tegenover elkaar verhouden: welke mensen hebben gelijkaardige vaardigheden, waar bevinden zich mogelijks gaps, ...
Om deze data inzichtelijk volgen we de typische stappen van een Analytics project: data gathering, data cleaning, data analyse en visualisatie. Dit proces werd daarna geoperationaliseerd om deze data voor elke AE'er toegankelijk te maken. In deze blog zullen we ingaan op elk van deze stappen.
Data gathering en cleaning
We hebben een lijst van mogelijke vaardigheden nodig en welke consultants deze vaardigheden hebben. Elke consultant heeft een AE CV in een Word document waarin deze vaardigheden opgelijst staan in bullet points. We zullen deze CV's automatisch overlopen en de vaardigheden eruit extraheren en vervolgens opkuisen.
Ten eerste moeten we de Word documenten omzetten naar een formaat dat het automatisch ontleden vergemakkelijkt. Word documenten zijn gestructureerde bestanden, waaruit we een XML-representatie kunnen afleiden. Voor deze stap gebruiken we een PowerShell script dewelke de laatst gewijzigde Engelstalige CV van elke consultant uit de portal haalt en met behulp van Apache Tika omvormt naar de XML-representatie.
$files = dir dump $Directory -rec -exclude "* ned*","*old*","* nl*","*.pdf"."*.xls","*-NED*"
$files | group directory | foreach {
$a = @($_.group | sort {[datetime]$_.lastwritetime} -Descending)[0]
$b = "xml\" + $a.Directory.Name + ".xml"
echo $a" to "$b;
java -jar tika.jar -r $a.FullName >> $b
}
Hieruit verkrijgen we een XML-bestand voor elke consultant:

De vaardigheden zijn terug te vinden als elementen tussen de hoofdstukken "Professional Skills" en "Professional Experience". Om de vaardigheden uit de XML-bestanden te kunnen extraheren, kunnen we XPATH queries in R gebruiken. R is een krachtige en uitbreidbare open source Analytics tool. We gebruiken R verder in deze blog nog om de vaardigheden te visualiseren, maar voorlopig gebruiken we enkel het XML package om de Word documenten te parsen.
doc = xmlInternalTreeParse(x,addAttributeNamespaces = FALSE) src = xpathSApply(doc, "(//p[following::p[contains(translate(text(), 'PROFESINALXRC', 'profesinalxrc'),'professional experience')] and preceding::p[contains(translate(text(), 'PROFESINALK', 'profesinalk'),'professional skills')] and (@class='opsomming' or @class='opsom2')])",xmlValue,simplify=TRUE)
Het resultaat hiervan is een lijst van vaardigheden, maar ons werk is nog niet gedaan. In de bullet points op een CV worden vaardigheden vaak gecombineerd in één zin (bv. "R & SAS"), er bevinden zich extra verklaringen naast de vaardigheden (bv. "experienced in ..."), of er wordt een tool op verschillende manieren geschreven: (bv. "Microsoft Systems Center", "MSSC", "MS Systems Center" ...), al dan niet met versienummers. Deze lijst moeten we nog verder opkuisen om de schrijfwijzes eenduidig te krijgen en onnodige woorden weg te halen.
Voor deze stap gebruiken we de uitstekende open source tool Open Refine. Via R exporteren we de lijst van geëxtraheerde vaardigheden van elke consultant naar een CSV-bestand waarin elke rij bestaat uit twee kolommen: de naam van de persoon en één enkele vaardigheid. Daarna voeren we op deze laatste kolom de volgende acties uit:
- Split op speciale tekens zoals '(', '&', ')', ...
- Verwijderen van spaties voor en na vaardigheden.
- Gelijkaardige skills samenvoegen en herleiden naar 1 schrijfwijze.
- Verwijderen van vaardigheden die we niet meenemen in de analyse.



Open Refine bevat een aantal hulpvolle operaties om hierbij te helpen, zoals automatische clustering van gelijkaardige vaardigheden en facetering om te sorteren op de meest voorkomende vaardigheden. Het resultaat van deze stap is een propere lijst van vaardigheden van elke consultant, die we kunnen gebruiken om te doorzoeken en te analyseren.
Data analyse en visualisatie
Een eerste ding dat we met de data over de vaardigheden van de consultants willen doen, is deze visualiseren. We willen weten welke consultants gelijkaardige vaardigheden hebben en dit op een intuïtieve manier visualiseren. Voor de visualisatie hebben we gekozen voor de Multidimensional Scaling (MDS) techniek: hierin worden de consultants verspreid in twee dimensies, waarbij consultants die "gelijkaardige" vaardigheden hebben dicht bij elkaar geplaatst en consultants die "minder gelijkaardige" vaardigheden hebben verder van elkaar. De mate waarin consultants "gelijkaardige" vaardigheden hebben, bepalen we door te kijken hoeveel skills consultants gemeenschappelijk hebben.
Om de MDS resultaten te berekenen gebruiken we opnieuw R - deze keer met het stats package. Het resultaat visualiseren we met behulp van D3.js, een JavaScript bibliotheek voor datavisualisatie, zoals hieronder weergegeven. Op deze manier krijgen we al een inzicht in welke consultants gelijkaardige vaardigheden hebben, welke groepen we hierin kunnen onderscheiden, welke consultants zeer specifieke vaardigheden hebben, etc.
(Open deze map in een nieuw venster)
Operationalisering
To make the cleaned-up list fully searchable, we used this list for the internal launch of an application of ours called Sk!lld.
Om de opgekuiste lijst van vaardigheden effectief doorzoekbaar te maken, hebben we deze lijst gebruikt voor de interne launch van Sk!lld. Het initiële idee voor Sk!lld kwam er tijdens de AE hackathon. Het is een webapplicatie waarin AE'ers kunnen zoeken op vaardigheden en waarin de consultants hun CV up-to-date kunnen houden. De profielen werden aangevuld met de lijst van vaardigheden en kunnen daarna in de applicatie doorzocht worden met behulp van Apache Solr. Onze collega's kunnen nu deze vaardigheden up-to-date houden binnen de applicatie, door aan te geven welke vaardigheden zij hebben of graag willen ontwikkelen.
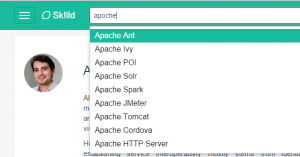
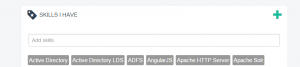
Sk!lld geeft ook suggesties op basis van de woorden die je ingeeft om te zoeken of op basis van de vaardigheden die zijn toegevoegd aan je profiel. De suggesties bekomen we door Analytics toe te passen - meer bepaald Association Rule Mining). Het algoritme gaat na welke sets van vaardigheden vaak tezamen voorkomen en welke regels hier uit afgeleid kunnen worden. Deze regels worden elke dag opnieuw berekend en in de search engine van Sk!lld geïntegreerd. Dit verlaagt de drempel om relevante vaardigheden toe te voegen aan profielen of gelijkaardige profielen te vinden. Voor de implementatie van het Association Rule Mining algorithme gebruiken we opnieuw R; deze keer met het arules package.
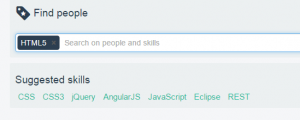
Organisaties bezitten vaak veel data die opgeslagen wordt in ongestructureerde formaten zoals tekstdocumenten. In deze blog beschreven we hoe je deze data kan transformeren naar gestructureerde informatie, deze data op een bruikbare manier kan visualiseren, en deze data beschikbaar kan maken.
Het voorbeeld dat we hiervoor gebruikten zijn de CV's van de AE consultants, waarin hun vaardigheden, projectervaringen, etc. beschreven staat. De informatie die we ontdekten in deze documenten bleek zo waardevol dat deze nu structureel ter beschikking wordt gesteld van elke AE'er, om op deze manier zeer snel de juiste persoon met de juiste vaardigheden te kunnen terugvinden. De applicatie gebruikt daarnaast ook Analytics technieken om de gebruikers actief te ondersteunen in hun zoektocht door zelf relevante suggesties te geven, wat het zoeken nog vergemakkelijkt.
Met dank aan Davy Sannen voor zijn hulp bij het schrijven van dit artikel
Wil je meer weten over wat Analytics voor jouw bedrijf kan betekenen? Contacteer ons voor meer informatie.



