

Een introductie tot ‘Churn Prediction’ op basis van een concrete case uit de bankenwereld.
Churn wordt typisch omschreven als ‘een klant die de organisatie verlaat’. Andere definities zijn echter ook mogelijk. Neem bijvoorbeeld de telecommarkt: men zou een een ‘churned customer’ kunnen omschrijven als een klant die de organisatie volledig verlaten heeft, als een klant die zijn/haar abonnement heeft verlaagd of opgezegd, als een klant die een bepaalde tijd niet actief is, etc.
Deze definitie is verschillend per organisatie, maar het is belangrijk dat je goed weet wat voor jouw bedrijf een ‘churned customer’ is.
In elk geval is het zo dat je aan deze klant minder zal verdienen dan in het verleden en dat je nieuwe klanten zult moeten vinden om dit verlies te compenseren. Salesmensen weten als geen ander dat het veel makkelijker is om bestaande klanten te behouden dan om er nieuwe aan te trekken. Volgens studies ligt de kost zo’n vijf maal hoger.
Naast deze kost zijn er nog andere economische voordelen aan klantenretentie. Langetermijnklanten kopen over het algemeen meer en kosten minder om te bedienen omdat je een duidelijk historisch beeld hebt van hun noden en wensen. Ze zijn ook minder gevoelig voor de marketing van je concurrenten.
Het positieve mond-aan-mondreclame van tevreden klanten is ook een uitstekende manier om nieuwe klanten te winnen: je ‘advocates’ ageren als ‘sales force multipliers’.
Churn voorkomen zorgt dus voor heel wat toegevoegde waarde.
Kan ik er iets aan doen?
Klantenretentie
Klantenretentieprogramma’s bestaan al een hele tijd. Aan het einde van de 18e eeuw deelden Amerikaanse handelaars koperen kentekens uit bij aankopen, die bij de volgende aankoop kon worden omgeruild. Om de kosten te verlagen, werden de kentekens vervangen door zegeltjes die verkregen werden bij het spenderen van een bepaald bedrag.

"Gold bond stamps". Licentie via CC BY-SA 2.5 via Wikipedia.
In het digitale tijdperk laten klanten een digitale voetafdruk na elke keer ze online gaan, iets op social media delen, een product aankopen, etc. Dit lever een hoop gegevens op: naast demografische informatie kennen we ook hun aankoopgeschiedenis, de evolutie van hun facturen, hoeveel keer ze de helpdesk contacteerden, etc.
Analytics laat ons toe om met slimme algoritmes modellen te bouwen die de complexe patronen uit deze gegevens naar boven halen. Op die manier bekomen we nieuwe inzichten in het gedrag van onze klanten en kunnen we hun toekomstige acties accurater voorspellen.
Een manier om deze inzichten toe te passen is via Customer Segmentation & Profiling via Descriptive Analytics algoritmes. Een andere interessante piste is om via Predictive Analytics algoritmes aan Churn Prediction te doen.
Churn Prediction
Inspanningen inzake klantenretentie zijn best gericht op klanten die je organisatie waarschijnlijk zullen verlaten. Dit is exact waar Churn Prediction bij helpt: het bouwen van statistische modellen die ‘churn scores’ berekenen voor je klanten en die aangeven hoe groot de kans is dat je hen zult verliezen.
Weten welke klanten dit precies zijn is niet voldoende: je moet ook weten waarom. En daarvoor moet je je klanten en hun gedrag goed begrijpen. Churn Prediction algoritmes voorzien je van deze informatie, gebaseerd op de door jou verzamelde data. Op basis van deze inzichten kan je je klanten op de juiste manier benaderen, met het juiste offer, op het juiste kanaal en op het juiste moment. Studies hebben aangetoond dat een dergelijke persoonlijke aanpak voor een duidelijk omschreven groep van klanten veel effectiever is dan eenzijdige massacommunicatie.
Het is ook belangrijk om de waarde van deze klanten voor je organisatie in beschouwing te nemen. Vaak zijn ‘low-value’ klanten de investering niet waard, zeker niet voor abonnementgedreven sectoren als telecom of utilities. Hier wordt waarde vaak uitgedrukt in termen van CLV (Customer Lifetime Value): een voorspelling van de verwachte winst gezien over de ganse toekomstige relatie met een klant. De berekening van deze waarde kan schommelen, gaande van harde berekeningen of heuristieken tot gesofisticeerde Predictive Analytics technieken.
Hoe begin ik eraan?
Het ontwikkelen van Analyticsmodellen is een iteratief en incrementeel proces. Meestal starten we van een eenvoudige basis (bvb. het toepassen van één algoritme op één bepaalde bron van data), evalueren we de kwaliteit van het bekomen model en interpreteren dan de resultaten.
Dit gebeurt zowel statistisch gezien als in businesstermen, samen met businessexperten. Op basis van deze resultaten wordt het model complexer gemaakt om de resultaten verder te verfijnen, aan de hand van meer databronnen of (een) nieuwe (combinatie van) algoritmes. Vaak zijn er meerdere iteraties nodig, telkens verder bouwend op de resultaten uit de vorige stappen.
Churn Prediction is een typisch voorbeeld van deze iteratieve en incrementele aanpak, zelfs wanneer je een eerste goed model hebt bekomen. Wanneer de potentiële ‘churners’ geïdentificeerd zijn, samen met hun redenen om de organisatie te verlaten, kan je hierop beginnen werken om deze klanten te behouden. Doe je dit goed, dan is de kans groot dat ze blijven.
Dit zal echter het huidige Churn Prediction model opheffen, waardoor er een nieuwe iteratie nodig is om te voorspellen wat in de gewijzigde situatie de belangrijkste ‘churn factors’ zijn. Pas dan kunnen er nieuwe succesvolle klantenretentie-acties opgezet worden.
Daarom is het noodzakelijk om dit proces een aantal keer te herhalen.
Case study: bank
Laten we de resultaten van een Churn Prediction model van een bank eens onder de loep nemen.
Het doel van het project was om ‘churners’ te identificeren op basis van demografische en gedragsmatige variabelen. In dit plaatje is een ‘churner’ iemand die minder producten bij de bank afneemt binnen de komende 3 maanden.
Er zijn verscheidene manieren waarop een klant minder producten kan hebben bij de bank: door het sluiten van een rekening, een kredietkaart of verzekeringsproduct te annuleren, … . In dit geval worden alle producten als gelijkwaardig beschouwd en wordt de churn berekend op basis van het aantal producten.
We beginnen met het berekenen van het CAR (Customer Analytics Record), dat uit een aantal variabelen bestaat om de klanten te karakteriseren. We gebruiken een combinatie van demografische en gedragsmatige variabelen. De demografische variabelen bestaan uit geslacht, leeftijd, opleidingsniveau en andere variabelen ter segmentatie die binnen de bank gebruikt worden. De gedragsmatige variabelen omvatten de periode hoe lang iemand klant is, zijn totale balans, het aantal producten bij de bank, kenmerken inzake hoeveel geld de klant verplaatst recent verplaatst heeft, etc. Op basis van deze data wordt een Churn Prediction model gebouwd dat voorspelt of een klant binnen de komende 3 maanden minder producten zal hebben bij de bank of niet.
Voor deze applicatie gebruikten we een Decision Tree algoritme. Trees zijn populair omdat ze hun dienst hebben bewezen in verscheidene sectoren en omdat ze goed interpreteerbare modellen opleveren. In essentie leiden Decision Trees automatisch een reeks van if-then-else regels af om data (hier: over de klanten) te classificeren in klassen (hier: churners vs niet-churners).
Het gegenereerde model kan makkelijk gevisualiseerd worden in een boomstructuur (vandaar de naam van het algoritme) om zo de resultaten te bespreken met de business experts binnen de organisatie. Dit is een belangrijk kenmerk, omdat we goed moeten weten waarom klanten zullen ‘churnen’ om zo een retentiestrategie op maat te kunnen toepassen.
Belangrijk om weten hierbij is dat we niet noodzakelijk op zoek zijn naar het model met de grootste predicatieve accuraatheid. Het beste Churn Prediction model is het model dat de beste inzichten oplevert opdat toekomstig churngedrag zo goed als mogelijk kan worden voorkomen.
Er zijn heel wat goede implementaties van een Decision Tree algoritme beschikbaar. Ik heb de open-source Rimplementation (onderdeel van het open-source R implementation in the rpart package) gebruikt om de Trees te berekenen en het rattle package om ze te visualiseren. De resultaten kunnen makkelijk geïntegreerd worden in bestaande software, ofwel door de R-functionaliteit te integreren ofwel door de verkregen if-then-else regels te herimplementeren.
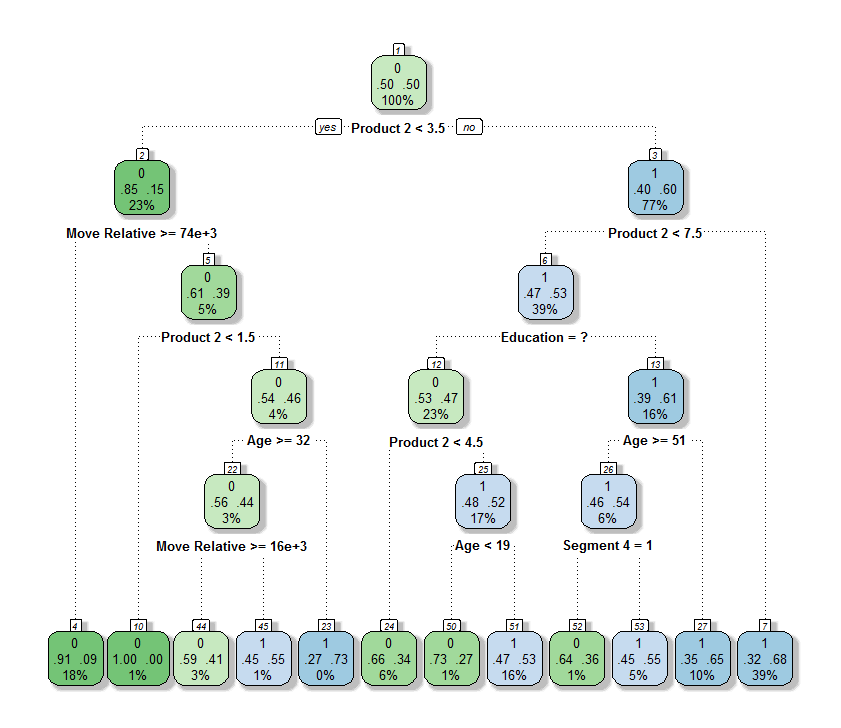
De bovenstaande figuur toont een voorbeeld-Decision Tree die we bekwamen voor onze specifieke churn prediction taak (de echte Tree kunnen we hier niet tonen omwille van confidentialiteitsredenen en we hebben de data ook gedeeltelijk geanonimiseerd door de namen van de variabelen te veranderen). Maar ook uit dit voorbeeld vallen een aantal interessante karakteristieken van de methode af te leiden.
The Tree lees je van boven naar beneden door de test onder een node te evalueren, via de juiste ‘branch’ tot je een ‘leaf’-node bereikt. De twee getallen temidden de nodes geven de churn scores weer voor klanten die in een bepaald ‘blad’ vallen. Hoe blauwer de nodes zijn, hoe groter de kans op churnen, hoe groener, hoe kleiner de kans. De percentages op de bodem van de nodes wijzen op het percentage van klanten dat in een bepaald leaf vallen.
Laten we uitgaan van een voorbeeld.
Stel dat een klant een waarde kleiner dan 3,5 heeft voor Product 2. Dit betekent dat we van de root node (Node 1) naar de linkse subtree schuiven, naar Node 2. In deze node bekijken we de variabele Move Relative. We stellen dat de waarde van deze variable groter is dan 74000. Dus moeten we opnieuw in de linkse subtree schuiven, naar Node 4. Dit is een leaf node (een node zonder een pad dat verder naar beneden loopt). Op dit punt nemen we een beslissing. We kunnen concluderen dat de churn score van deze klant in dit voorbeeld 9% bedraagt, zoals aangegeven in de leaf node waar we terechtgekomen zijn.
Het bestuderen van een Decision Tree kan heel wat interessante inzichten opleveren in verband met welke klanten churners zijn:
- Sommige CAR-variabelen worden niet gebruikt in de Tree. Dit belicht een andere interessante eigenschap van Decision Tree algoritmes: ze selecteren automatisch de meest relevante variabelen om een gegeven taak uit te voeren en negeren de rest. Zo krijg je een beeld van de variabelen die relevant zijn bij het bepalen van de churners. Uit het algoritme bleek bijvoorbeeld dat de tijd die een persoon al klant was bij de bank geen impact had op de churn scores.
- Sommige CAR-variabelen worden meermaals gebruikt in de Tree. Hierdoor kan het algoritme verschillende churn scores toewijzen aan verschillende waarden van een bepaalde variabele. Neem bijvoorbeeld de variable Move Relative, die twee keer in de tree voorkoomt (in Node 2 en in Node 22). We zien dat in het algemeen de kans op churning groter wordt wanneer de waarde van deze variabele afneemt. Er is natuurlijk ook een wisselwerking met andere variabelen. Het manueel opsporen zou heel moeilijk zijn, terwijl het algoritme ze automatisch voor je vindt.
- De afwezigheid van informatie kan ook handig zijn. Education bijvoorbeeld is een waarde die niet gekend is voor elke klant. In Node 6 wordt deze informatie echter gebruikt om de voorspellingen van het model te verbeteren: als Education niet gekend is (er staan dan een vraagteken in plaats van de waarde), valt de churn score meestal lager uit.
Let wel: dit is niet noodzakelijk de Decision Tree met de hoogste predicatieve accuraatheid. Het is echter wel een goed model dat gemakkelijk kan geïnterpreteerd worden en op basis waarvan acties kunnen worden ondernomen. Het toevoegen van extra variabelen en het doen groeien van de tree zal tot een hogere predicatieve accuraatheid leiden, maar hij zal minder goed interpreteerbaar zijn. Dit zou handig zijn bij applicaties waarin het erg belangrijk is dat zo nauwkeurig mogelijk wordt voorspeld of een klant zal churnen, maar niet zozeer waarom dat gebeurt (bvb. als input voor een Customer Lifetime Value inschatting).
Based on the predictions and insights obtained from this tree, well-targeted customer retention actions can be set up.
Op basis van de voorspellingen en inzichten die uit de Tree voortkomen, kunnen we erg gerichte klantenretentie-acties opzetten.
Conclusies en Takeaways
Wanneer klanten churnen kost je dat inkomsten en moet je nieuwe klanten zien aan te trekken. Omdat die kost veel hoger ligt dan het behouden van je bestaande klanten, worden klantenretentie-acties opgezet om churn te verkleinen. Churn Prediction is een Predictive Analysis techniek die je toelaat je retentie-inspanningen gerichter te doen en ze kosten-efficiënter te maken. Het is typisch een iteratief en incrementeel proces, want het huidige Churn Prediction model raakt achterhaald wanneer je inspanningen om je churn factors te beïnvloeden hun vruchten afwerpen. Daarom is het belangrijk dat je het model vindt dat je de beste inzichten oplevert om churngedrag te voorkomen, niet het model met de grootste statistische accuraatheid. Hiervoor gebruikten we het voorbeeld van een bankcase.
Enkele belangrijke takeaways:
- Business engagement: betrek business vroeg in het proces en hou hen doorlopend betrokken. Zorg ervoor dat ze je model of analysemethode begrijpen en erin geloven. Business is een niet te missen schakel in elk Analyticsproject.
- Kwaliteit boven kwantiteit: data van hogere kwaliteit is belangrijker dan grote hoeveelheden data. Zorg ervoor dat je data clean en up-to-date is voor je het in een model of analyse gebruikt.
- Think big, act small: probeer het probleem niet in een keer op te lossen. Liever kleinschaliger beginnen, met een beperkte set van data en technieken, om zo sneller toegevoegde waarde te laten zien. Daarna is het een kwestie van itereren en stapsgewijs meer complexiteit toe te voegen, gebaseerd op de inzichten die je eerder hebt verworven. Zorg er wel altijd voor dat je je einddoel niet uit het oog verliest!
- Beperk je niet tot ‘text book’ voorbeelden: er bestaan heel wat verschillende benaderingen en technieken. Kies degenen die het beste bij jouw applicatie passen. Door te experimenteren zal je ervaring opbouwen en een buikgevoel kweken voor welke aanpak bij welke situatie past. Meestal levert een combinatie van verscheidene databronnen en Analyticstechnieken het beste resultaat op.



{kind=link}