Heb je je ooit afgevraagd hoe je klanten zich op grote schaal gedragen? Weet je welke klanten het meest waardevol zijn en via welke klanten je opportuniteiten kan aanboren? Mogelijks heb je een algemeen beeld van het gedrag van je klanten – op basis van hun gedrag uit het verleden – maar is dat beeld ook gebaseerd op feiten of data?
Het is mogelijk om op basis van hun gedrag – en statische karakteristieken zoals demografie – je klanten in gelijkaardige groepen te categoriseren. Het idee hierachter is dat je altijd patronen kan vinden in de acties van je klanten, ongeacht hoe willekeurig en verspreid die ook op het eerste gezicht mogen lijken.
Beeld je in door een supermarkt te wandelen met of zonder boodschappenlijstje. De dingen die je koopt zijn voor jezelf eerder willekeurig afgaand op het grote assortiment in de rekken. Voor de supermarkt is dat echter niet het geval: die anticipeert op wat je gaat kopen op basis van je eerder gedrag en van klanten die zich gedragen ‘zoals jij’.
Waarom is dit belangrijk voor mij?
Je klant kennen en weten hoe hij of zij zich gedraagt, is cruciaal voor business succes: door in te spelen op uniciteit behaal je behaal competitief voordeel. Pas wanneer je de eigenaardigheden van je klanten kent, kan je hen op hun wenken bedienen, zonder daarbij opkomende trends uit het oog te verliezen.
Een goed voorbeeld van hoe het niet moet is Kodak. Kodak vroeg in 2012 het faillissement aan na jaren van negatieve balansen. Jammer genoeg waren ze niet in staat om in te spelen op de digitale camera-trend; ze gingen er van uit dat hun klanten wel zouden blijven.
Procter and Gamble daarentegen is een voorbeeld van een bedrijf dat het wel goed aangepakt heeft – en ook goed met haar klanten communiceert. P&G produceert een reeks van huishoudproducten, m.a.w. een van de ‘target personas’ is de persoon die deze producten koopt. Vaak is dat de moeder. Het volgende spotje illustreert goed hoe ze inspelen op de gevoelens van de kijker en daarnaast effectief communiceren over de waarde die ze voor hun doelpubliek opleveren.
[embed]https://www.youtube.com/watch?v=5KlS45U7-O4[/embed]
Mijn klant begrijpen: hoe begin ik eraan?
In een klassieke setting gebeurt de segmentatie van een klantenbestand vaak met beperkte input van business of van de mensen die dagelijks met de klant in contact komen. De data scientist verzamelt de data en stelt een segmentatie voor die plausibel oogt, maar daarom niet helemaal overeenstemt met je buikgevoel.
Een meer business-gerichte aanpak zal eerst de relaties tussen je klanten en hun gedrag gaan visualiseren en feedback geven aan business over de gedane ontdekkingen tijdens het segmentatieproces. De laatste stap – en het uiteindelijke doel – is om al deze segmenten te ‘profilen’ om een duidelijke beschrijving en een beeld te krijgen van welk segment welk type klant representeert.
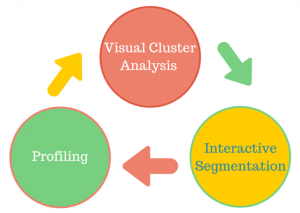
Het potentieel van deze methode kunnen we aantonen aan de hand van een recente case voor een bedrijf dat allerhande professionele trainingen en cursussen organiseer voor andere bedrijven of professionals. Het opzet van de analyse was om een profiel van ‘goede’ klanten op te stellen. ‘Goed’ werd hier omgeschreven in termen van frequentie en financiële waarde, m.a.w. hoe vaak een klant een cursus bijwoont en hoeveel hij of zij spendeert aan training.
1. Visual Cluster Analyse
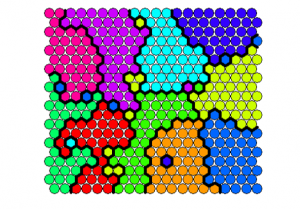
Door een visuele analyse van de variabelen en het plotten van de variabelen op een heat map kunnen we snel valideren of de data de verwachtingen van de business bevestigt of weerlegt. Voor het plotten gebruiken we een de techniek van de self-organizing maps.

De verschillende nodes op elke heat map bevatten dezelfde klanten. Hoe dichter bepaalde nodes bij elkaar liggen, hoe meer overeenkomsten er zijn tussen de klanten binnen deze nodes. Hoe verder uit elkaar, hoe minder gelijkenissen tussen de klanten in de nodes. Rode nodes voor een bepaalde variabele wijzen op een hoge concentratie van dit type klanten binnen deze node. Wanneer een node wit is, wil dit zeggen dat er geen klanten zijn binnen die node met die bepaalde karakteristiek.
Uit het bovenstaande voorbeeld kunnen we concluderen dat goede klanten bedrijven zijn met een gemiddeld aantal werknemers en dat ze vaak niet geïnteresseerd zijn in HR cursussen. Deze informatie wordt vervolgens visueel voorgesteld aan de business ter bevestiging of om de business te wijzen op voorheen onbekende patronen in de data.
2. Interactieve segmentatie
De volgende stap is om aan de hand van deze informatie clusters van klanten te vormen gebaseerd op eerder gedefinieerde variabelen. Dit gebeurt aan de hand van een clustering algoritme dat gelijkaardigheid binnen een cluster maximaliseert en gelijkaardigheid tussen clusters minimaliseert. Het algoritme baseert zich hiervoor op variabelen die de populatie beschrijven.
We spreken van ‘interactieve’ segmentatie omdat het uiterst belangrijk is dat deze stap gebeurt samen met de business. Enkel zo kunnen we bijvoorbeeld te weten komen welke clusters van tel zijn vanuit businessperspectief.
3. Profiling
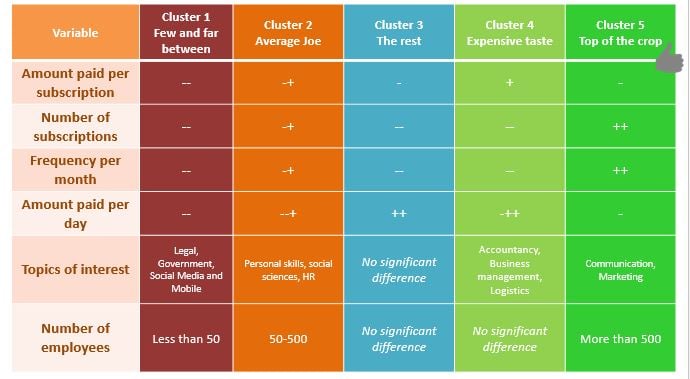
Profiling is de derde en laatste stap en maakt het verschil tegenover traditionele segmentatieprocessen. Het doel van deze stap is om een profiel of beschrijving te creëren voor elke cluster die we identificeerden, met een focus op het specifieke doel dat we aan het begin van het project hebben gesteld. We gebruiken hierbij variabelen die we eerder gebruikten in het clusteralgoritme en descriptieve variabelen die niet gebruikt werden bij het feitelijke clusteren.
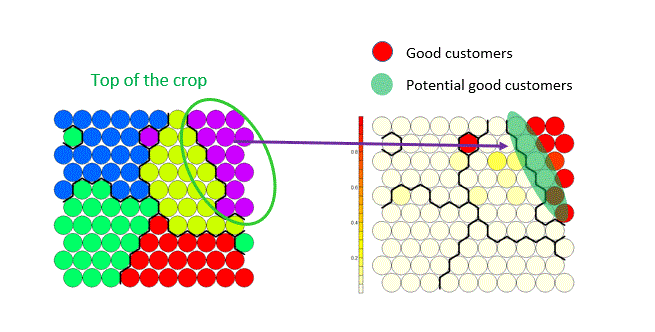
We bekomen een duidelijke beschrijving van elke cluster in relatie tot alle andere. Nu focussen we ons op de cluster waarin zich de meeste ‘target customers’ bevinden. Voor dit specifieke project waren we vooral geïnteresseerd in te weten wie ‘goede klanten’ zijn. In dit geval zijn dat de klanten in cluster 5 en we noemen deze daarom de ‘Top of the crop’. Daarna confirmeerde de business dat dit effectief voor hen de ‘beste’ goede klanten waren.
Door het plotten van het aantal klanten in elke cluster tegenover het totale aantal geld gespendeerd per cluster konden we nagaan hoe waardevol de ‘Top of the crop’ eigenlijk was voor de business.
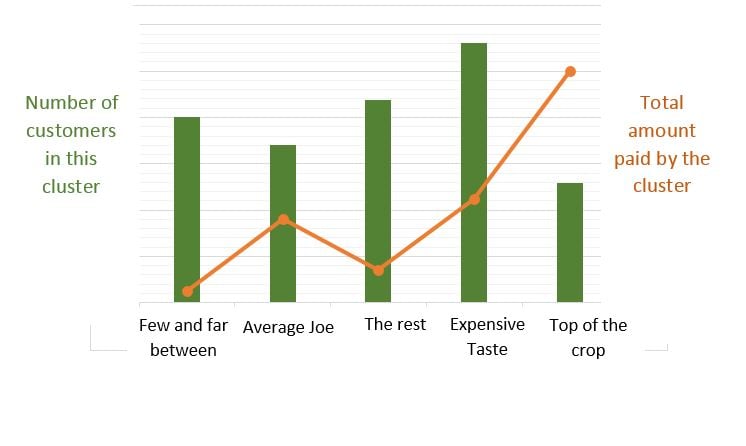
En nu?
Een verdere analyse van de ‘Top of the crop’ cluster toonde aan dat hoewel deze cluster een groot aantal ‘goede’ klanten bevatte, er ook een aantal klanten in zaten die slechts ‘bijna goed’ waren. Deze groep bezit een groot potentieel: ze zijn het ideale doelwit van een marketingcampagne, omdat ze slechts een klein duwtje nodig hebben om ‘goede klant’ te worden volgens de definitie van de business.
Deze case study toont aan dat het niet nodig is om heel wat data van je klant te verzamelen om hem te leren kennen of om zwaar te investeren in gespecialiseerde data-analysesoftware. De data die al ter beschikking is binnen je organisatie is vaak al voldoende om van start te gaan en je klanten op basis van gelijkaardige karakteristieken te segmenteren. We implementeerden deze segmentatiemethode met de open source tool R (The R Project for Statistical Computing, gebruik makend van een aantal beschikbare libraries zoals kohonen en NbClust (gratis beschikbaar via Comprehensive R Archive Network (CRAN). Dank aan mijn voormalig professor en goede vriend, prof. Dr. Bart Baesens, wiens research team de paper A new SOM-based method for profile generation: Theory and an application in direct marketing publiceerde en waarop we ons inspireerden om deze segmentatiemethode te ontwikkelen.
Zoals met elk analyseproject zijn rapid prototyping en klein durven beginnen de sleutel tot het creëren van concurrentievoordeel. Niets houd je tegen om vandaag nog te starten met het analyseren van de reeds beschikbare data om eenvoudige maar haalbare modellen en analyses te bekomen. Aan de hand van dit minimum lovable product zal je organisatie een vlucht vooruit nemen qua creatief denken en samenwerking. Deze resultaten zijn misschien ook wat je nodig hebt om stakeholders en managers te overtuigen van het potentieel dat verborgen zit in je data.
“A good plan violently executed now is better than a perfect plan executed at some indefinite time in the future.” - George S. Patton Jr.
Andere punten om te onthouden:
- Naast rapid prototyping is het belangrijk om naar een ambitieus end-game toe te werken. Dit kan in stappen: think big, act small.
- Betrek de business van in het begin en hou dit aan gedurende het hele proces. Business is je klant en moet je model/analyse begrijpen en erin geloven. Ga niet uit van veronderstellingen.
- Goede data is de sleutel tot succes. Bruikbare data is daarbij beter dan big data. Zorg ervoor dat de data die je hebt clean, relevant en up-to-date is.
- Wees niet bang om te experimenteren met verschillende methodes. Probeer verschillende technieken voor verschillende doeleinden, volg niet enkel de schoolvoorbeelden.
- Data, modellen, buikgevoel en intuïtie vormen de perfecte mix; gebruik ze dus allemaal.
- Je klanten kennen en aan hun behoeftes beantwoorden zal je helpen een goede strategie te bepalen. Want het succes van je organisatie hangt af van of je klanten gelukkig zijn of niet.